
We live in a time where wearable/mobile products comprised of sensors, apps, AI and IoT (AIoT) technology are part of everyday life. Every year we hear about amazing advances in processor technology and AI algorithms for all aspects of life from industrial automation to futuristic biomedical products.
For developers, the requirement to design low-cost products with better battery life, higher computational performance and analytical accuracy, requires access to a suite of affordable processor technology, algorithmic libraries, design tooling and support.
This article aims to provide developers with an overview of all salient points required for algorithm implementation on Arm Cortex-M processors.
Can you give me a concrete example?
Almost all IoT sensor applications require some level of signal processing to enhance data and extract features of interest. This could be temperature, humidity, gas, current, voltage, audio/sound, accelerometer data or even biomedical data.
Consider the following application for gas concentration measurement from an Infra-red gas sensor. The requirement is to determine the amplitude of the sinusoid in order to get an estimate of gas concentration – where the bigger amplitude is the higher the gas concentration will be.
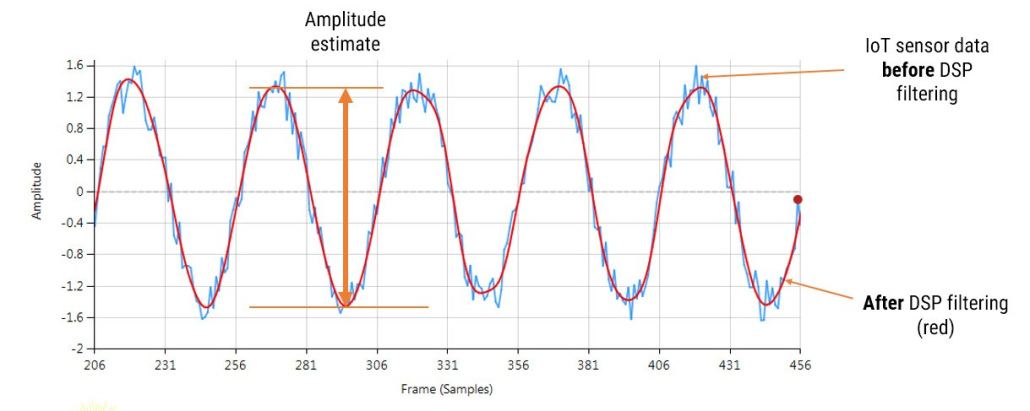
Analysing the figure, it can be seen that the sinusoid is corrupted with measurement noise (shown in blue), and any estimate based on the blue signal will have a high degree of uncertainty about it – which is not very useful for getting an accurate reading of gas concentration!
After cleaning the sinusoid with a digital filter (red line), we obtain a much more accurate and usable signal for our gas concentration estimation challenge. But how do we obtain the amplitude?
Knowing that the gradient at the peaks is zero, a relativity easy and robust way of finding the peaks of the sinusoid is via numerical differentiation, i.e. computing the difference between sample values and then looking for the zero-crossing points in the differentiated data. Armed with the positions and amplitudes of the peaks, we can take the average and easily obtain the amplitude and frequency. Notice that any DC offsets and low-frequency baseline wander will be removed via the differentiation operation.
This is just a simple example of how to extract the properties of a sinusoid in real-time using various algorithmic IP blocks. There are of course a number of other methods that may be used, such as complex filters (analytic signals), Kalman filters and the FFT (Fast Fourier Transform).
Arm Cortex-M processor technology
Although a few processor technologies exist for microcontrollers (e.g. RISC-V, Xtensa, MIPS), over 90% of the microcontrollers used in the smart product market are powered by so-called Arm Cortex-M processors that offer a combination of high algorithmic performance, low-power and security. The Arm Cortex-M4 is a very popular choice with several silicon vendors (including ST, TI, NXP, ADI, Nordic, Microchip, Renesas), as it offers DSP (digital signal processing) functionality traditionally found in more expensive devices and is low-power.
Algorithmic libraries and support
An obvious hurdle for many developers is how to port their algorithmic concept or methods from Python/Matlab into embedded C for real-time operation? This is easier said than done, as many software engineers are not well-versed in understanding the mathematical concepts needed to implement algorithms. This is further complicated by the challenge of how to implement algorithms developed by researchers that are not interested/experienced in developing real-time embedded applications.
A possible solution offered by the Mathworks (Embedded Coder) automatically translates Matlab algorithms and functions into C for Arm processors, but its high price tag and steep learning curve make it unattractive for many.
That being said, Arm and its rich ecosystem of partners provide developers with extensive easy-to-use tooling and tried and tested software libraries. Arm’s CMSIS-DSP and CMSIS-NN frameworks for algorithm development and machine learning (ML) are two very popular examples that are open source and are used internationally by tens of thousands of developers.
The Arm CMSIS-DSP software framework is particularly interesting as it provides IoT developers with a rich collection of fast mathematical and vector functions, interpolation functions, digital filtering (FIR/IIR) and adaptive filtering (LMS) functions, motor control functions (e.g. PID controller), complex math functions and supports various data types, including fixed and floating point. The important point to make here is that all of these functions have been optimised for Arm Cortex-M processors, allowing you to focus on your application rather than worrying about optimisation.
The Arm-CMSIS framework solutions are strengthened by Arm partners ASN and Qeexo who provide developers with easy-to-use real-time filtering, feature extraction and ML tooling (AutoML) and reference designs, expediting the development of IoT applications, including industrial, audio and biomedical. These solutions have been optimised for Arm processors with the help of Arm’s architecture experts and insider knowledge of compiler workings.
A benchmark of ASN’s floating point application-specific DSP filtering library versus Arm’s CMSIS-DSP library is shown below for three types of Arm cores.
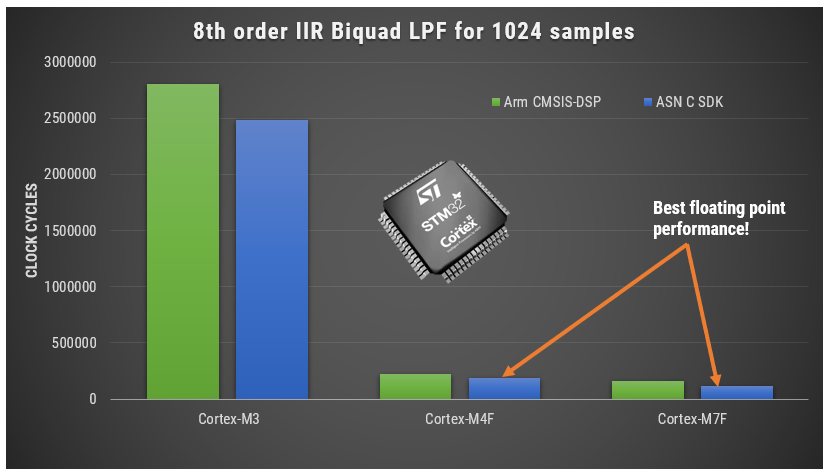
As seen, the performance of the ASN library is slightly faster by virtue of the application-specific nature of the implementation. The C code is automatically generated from the ASN Filter Designer tool.
Cortex-M4 and Cortex-M7
The Arm Cortex-M4 processor and its more powerful bigger brother the Cortex-M7 are highly-efficient embedded processors designed for IoT applications that require decent real-time signal processing performance and memory.
Both the Cortex-M4 and M7 core benefit from the Armv7E-M architecture that offers additional DSP extensions. Depending on the flavour of the processor, the M4F/M7F processors implement DSP hardware accelerated instructions (SIMD), as well as hardware floating point support via an FPU (floating point unit), giving them a significant performance boost over the Cortex-M3. The ‘F’ suffix signifies that the device has an FPU.
This lends itself to the efficient implementation of much more computationally intensive DSP and ML algorithms needed for more advanced IoT products and real-time control applications requiring highly deterministic operations.
Microcontrollers based on the M4F or M7F, usually offer many of the hardware peripheral and connectivity advantages of the simpler M3, providing developers with a very powerful, low-power development platform for their IoT application. The Cortex-M7F typically offers much higher performance than its Cortex-M4F little brother, doubling the performance on FFT, digital filters and other critical algorithms.
Floating point or fixed point?
The hardware floating point support unit expedites RAD (rapid application development), as algorithms and functions developed in Matlab or Python can be ported to C for implementation without the need for a lengthy data arithmetic quantisation analysis. Although floating point comes with its own problems, such as numeric swamping, whereby adding a large number to a small number ignores the smaller component. This can become troublesome in digital filtering applications using the standard Direct Form structure. It is for this reason that all floating-point filters should be implemented using the Direct Form Transposed structure, as discussed in the following article.
Correctly designing and implementing these tricks requires specialist knowledge of signal processing and C programming, which may not always be available within an organisation. This becomes even more frustrating when implementing new algorithms and concepts, where the effects of the arithmetic are yet to be determined.
Single vs double precision floating point
For a majority of IoT applications single precision (32-bit) floating point arithmetic will be sufficient, providing approximately 7 significant digits of precision. Double precision (64-bit) floating point provides approximately 15 significant digits of precision, but in truth should only be used in applications that require more than 7 significant digits of precision. Some examples include: FFT based noise cancellation, CIC correction filters and Rogowski coil compensation filters.
Some Cortex-M7F’s (e.g. STM32F769) implement a Double precision FPU providing an extra performance boost to high numerical accuracy IoT applications.
Fixed point
Fixed point is not necessarily less accurate than floating point, but requires much more quantisation analysis, which becomes tricky for signals with a wide dynamic range. As with floating point careful analysis is required, as weird effects can appear due to the level of quantisation used, leading to unreliable behaviour if not properly investigated. It is this challenge that can slow down a development cycle significantly, in some cases taking months to validate a new algorithm.
Many developers have traditionally considered devices without an FPU (e.g., Cortex-M0/M3) as the best choice for low-power battery applications. However, when comparing a modern Cortex-M7 device manufactured using 40nm semiconductor process technology, to that of a ten-year-old Cortex-M3 using 180nm process technology, the Cortex-M7 device will likely have a lower power profile.
Acceleration of DSP calculations
The Armv7E-M architecture supports a DSP extension that implements an SIMD (single instruction, multiple data) architecture extension that can significantly improve the performance of an algorithm. The basic idea behind SIMD involves parallel execution of an instruction (eg. Add, Subtract, Multiply, Divide, Abs etc) on multiple data elements via the use of 64 or 128-bit registers. These DSP extension intrinsics (SIMD optimised instruction) support a variety of data types, such as integers, floating and fixed-point.
The high efficiency of the Arm compiler allows for the automatic dissemination of your C code in order to break it up into SIMD intrinsics, so explicit definition of any DSP extension intrinsics in your code is usually unnecessary. The net result for your application is much faster code, leading to better power consumption and for wearables, better battery life.
What algorithmic operations would use this?
The following examples give an idea of operations that can be significantly speeded up with SIMD intrinsics:
- vadd can be used to expedite the calculation of a dataset’s mean. Typical applications include average temperature/humidity readings over a week, or even removing the DC offset from a dataset.
- vsub can be used to expedite numerical differentiation in peak finding, as discussed in the example above.
- vabs can be used for expediting the calculation of an envelope of a fullwave rectified signal in EMG biomedical and smartgrid applications.
- vmul can be used for windowing a frame of data prior to FFT analysis. This is also useful in audio applications using the overlap-and-add method.
The hardware floating point unit is very good for expediting MAC (multiply and accumulate) operations used in digital filtering, requiring just three cycles to complete. Other DSP operations such as add, subtract, multiply and divide require just one cycle to complete.
Combining DSP, low-power and security: The Cortex-M33
The Arm Cortex-M33 is based on the Armv8-M architecture and is a step up from the Cortex-M4 focusing on algorithms and hardware security via Arm’s TrustZone technology and memory-protection units. The Cortex-M33 processor attempts to achieve an optimal blend between real-time algorithmic performance, energy efficiency and system security.
TrustZone technology
Arm TrustZone implements a security paradigm that discriminates between the running and access of untrusted applications running in a Rich Execution Environment (REE) and trusted applications (TAs) running in a secure Trusted Execution Environment (TEE). The basic idea behind a TEE is that all TAs and associated data are secure as they are completely isolated from the REE and its applications. As such, this security model provides a high level of security against hacking, stealing of encryption keys, counterfeiting, and provides an elegant way of protecting sensitive client information.
State-of-the art AI microcontrollers
Released in 2020, the Arm Cortex-M55 processor and its bigger brother the Cortex-M85 are targeted for AI applications on microcontrollers. These processors feature Arm’s new Helium vector processing technology based on the Armv8.1-M architecture that brings significant performance improvements to DSP and ML applications. However, as only a few IC vendors (Alif, Samsung, Renesas, HiMax, Bestechnic, Qualcomm) have currently released or are planning to release any devices, Helium processors remain a gem for the future.
Key takeaways
Arm and its rich ecosystem of partners provide IoT developers with extensive easy-to-use tooling and tried and tested software libraries for designing an implementing IoT algorithms for their smart products. Arm Cortex-MxF processors expedite RAD by virtue of their ease of use and hardware floating-point support, and modern semiconductor technology ensures low-power profiles making the technology an excellent fit for IoT/AIoT mobile/wearables applications.








