The internet of things (IoT) has gained tremendous popularity over the last few years, as many organisations strive to add IoT smart sensor technologies to their product portfolios. The basic paradigm centres around connecting everything to everything, and exchanging all data. This could be house hold appliances to more blue sky applications, such as smart cities. But what does this particularly mean for you?
Almost all IoT applications involve the use of sensors. But how do SME and even multi-national organisations transform their legacy product offering into a 21st century IoT application? One the first challenges that many organisations face is how to migrate to an IoT application while balancing design time, time to market, budget and risk.
Sounds interesting? Then read further….
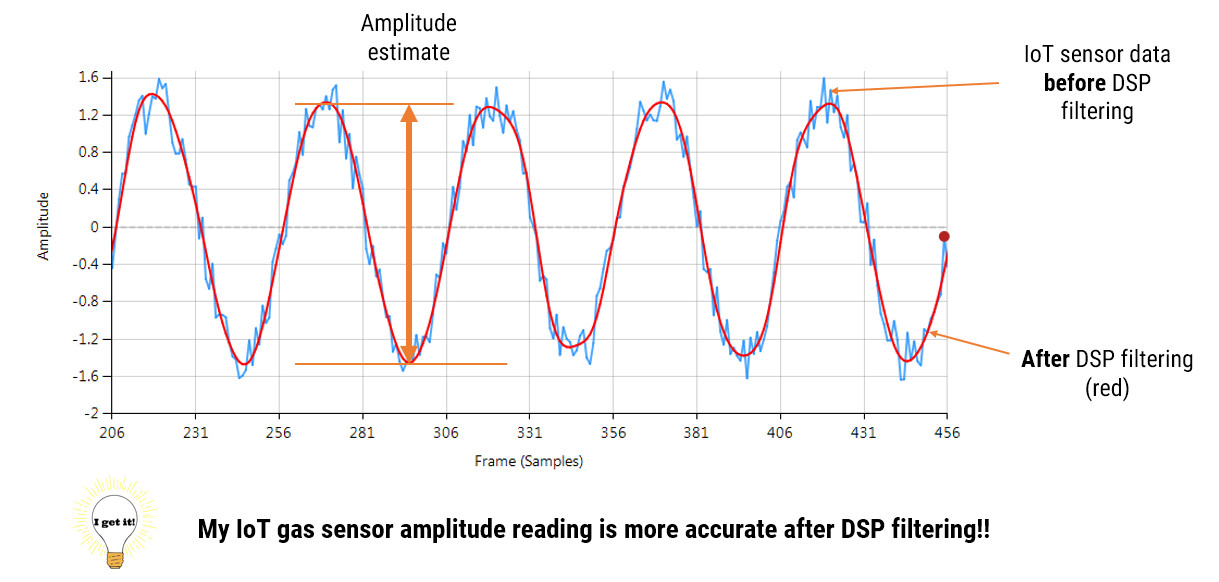
We recently completed a project for a client who manufactured their own sensors, but wanted to improve their sensor measurement accuracy from ±10% to better than ±0.5% without going down the road of a massive re-design project.
The question that they asked us was simply: “Is it possible to get high measurement accuracy performance from a signal that is corrupted with all kinds of interference components without a hardware re-design?”
Our answer: “Yes, but the winning recipe centres around knowing what architectural building blocks to use”.
Traditionally, many design bureaus will evaluate the sensor performance and try and improve the measurement accuracy performance by designing new hardware and adding a few standard basic filtering algorithms to the software. This sort of intuitive approach can lead to very high development costs for only a modest increase in sensor performance. For many SMEs these costs can’t be justified, but perhaps there’s a better way?
Algorithms: the winning recipe
Algorithms and mathematics are usually regarded by many organisations as ‘academic black magic’ and are generally overlooked as a solution for a robust IoT commercial application. As a consequence very few organisations actually take the time to analytically analyse a sensor measurement problem, and those who do invent something tend to come up with something that’s only useable in the lab. There has been a trend over the years to turn to Universities or research institutes, but once again the results are generally too academic and are based more on getting journal publications, rather than a robust solution suitable for the market.
Our experience has been that the winning recipe centres around the balance of knowing what architectural blocks to use, and having the experience to assess what components to filter out and what components to enhance. In some cases, this may even involve some minor modifications to the hardware in order to simplify the algorithmic solution. Unfortunately, due to the lack of investment in commercially experienced, academically strong (Masters, PhD) algorithm developers and the pressure of getting a project to the finish line, many solutions (even from reputable multi-national organisations) that we’ve seen over the years only result in a moderate increase in performance.
Despite the plethora of commercially available data analysis software, many organisations opt to do basic data analysis in Microsoft Excel, and tend to stay away from any detailed data analysis as it’s considered an unnecessary academic step that doesn’t really add any value. This missed opportunity generally leads to problems in the future, where products need to be recalled for a ‘round of patchwork’ in order solve the so called ‘unforeseen problems’. A second disadvantage is that performance of the sensors may be only satisfactory, whereas a more detailed look may have yielded clues on how make the sensor performance good or in some cases even excellent.
Algorithms can save the day!
“Although many organisations regard data analysis as a waste of money, our experience and customers prove otherwise.”
Investing in detailed data analysis at the beginning of a project usually results in some good clues as to what needs to be filtered out and what needs to be enhanced in order to achieve the desired performance. In many cases, these valuable clues allow experienced algorithm developers to concoct a combination of signal processing building blocks without re-designing any hardware – which is very desirable for many organisations! Our experience has shown that this fundamental first step can cut project development costs by as much as 75%, while at the same time achieving the desired smart sensor measurement performance demanded by the market.
So what does this all mean in the real world?
Returning the story of our customer, after undertaking a detailed data analysis of their sensor data, our developers were able design a suitable algorithm achieving a ±0.1% measurement accuracy from the original ±10% with only minor modifications to the hardware. This enabled the customer to present his IoT application at a trade show and go into production on time, and yes, we stayed within budget!